How we built a fact-check radar for a creator in two days
A German creator with a large audience in nutrition and fitness debunks viral misinformation for a living. Finding what to debunk was hours of doomscrolling a week. We built a radar that does the scrolling: it watches three platforms, checks every claim in three adversarial AI passes, and hands over an inbox where the human decides. Client details are anonymized; the architecture is real.
Published July 2026 by Balázs Turán, Creative Data Engineers.
What we built
→A scheduled radar over three platforms: German-language YouTube (with transcripts), TikTok keyword discovery, and an Instagram watchlist, scanned around the clock.
→Three AI passes per claim: extract with a verbatim quote that code re-verifies against the transcript, grade against a curated library of documented falsehoods, then an adversarial pass that tries to defend the claim. Only claims that survive all three reach a human.
→A review inbox, never an autopublisher: the creator accepts or rejects; accepting emails the team; rejections teach the judge.
→Built in two days on React, Supabase edge functions, and Claude models that are swappable per stage.
Why we built it
Debunking scales badly when discovery is manual
The creator's format works: take a viral false health claim, show why it is wrong, cite the science. The bottleneck was never the debunking, it was the finding. Viral misinformation spreads across three platforms in parallel, and by the time you spot it by hand, the wave has often passed. The brief was simple: never miss a big one again, and never waste a morning scrolling for it.
The hard constraint came from the output. A tool that suggests "react to this person, they are lying" must not be wrong. A missed claim costs a video idea; a false accusation costs credibility, and possibly a lawyer. So the whole system is built for precision first, and everything public stays behind a human decision.
The system
Collect, verify adversarially, let the human decide
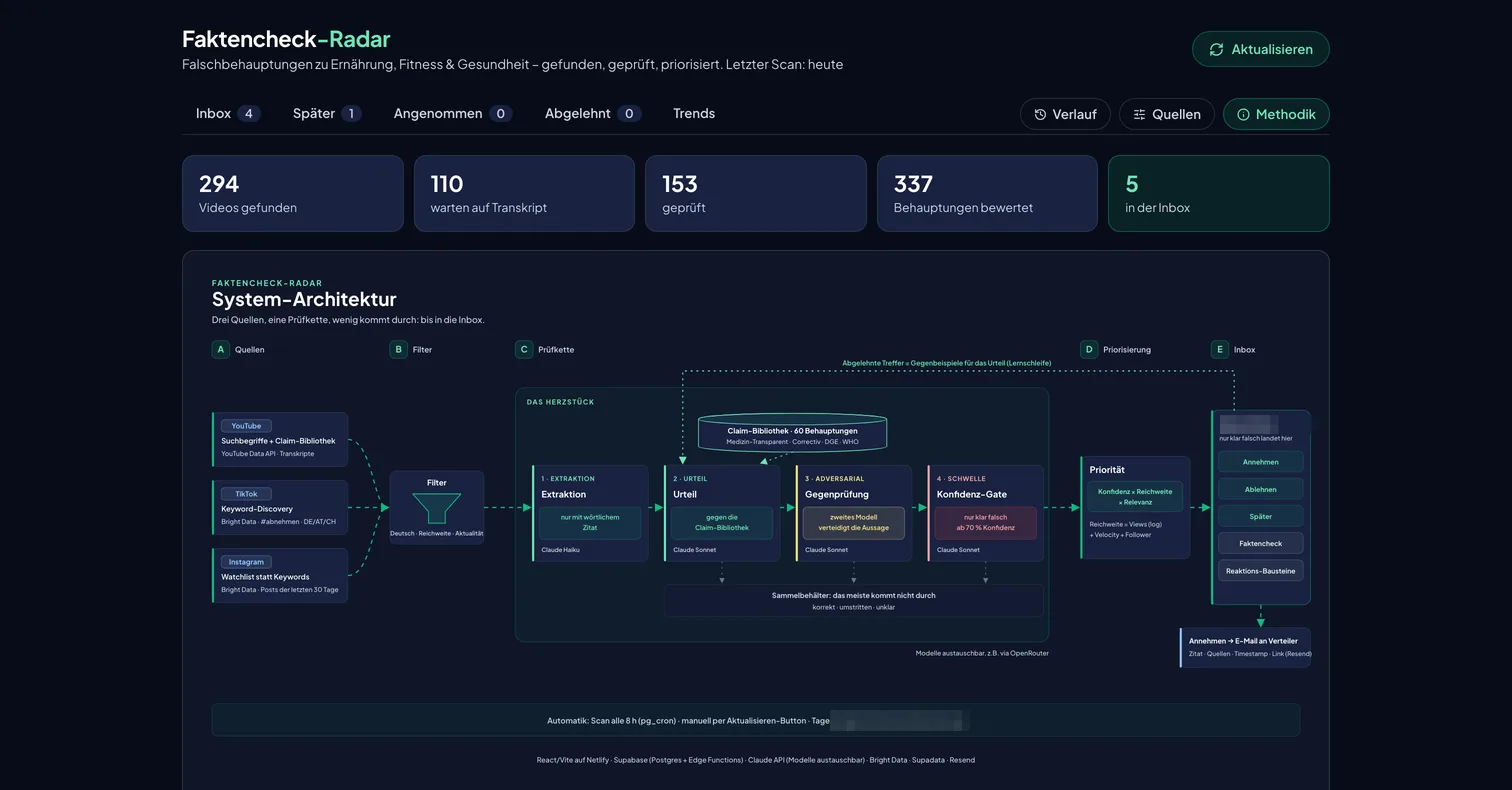
Three bands: watch the feeds on a schedule, check every claim in three passes that get progressively more skeptical, and a person decides in a ranked inbox. One loop closes the system: rejections flow back as counterexamples.
Sources we pullOur pipelineAI checksHuman decides
Hover or focus any box for a plain-language explanation.
Under the hood: a React app and Supabase edge functions, Claude models swappable per stage, a hard daily AI budget cap that the functions reserve against before spending, and prompt-injection defenses that treat all scraped text as untrusted data. The whole build took two days; the method it encodes took years of watching one-pass AI tools be confidently wrong.
What it looks like
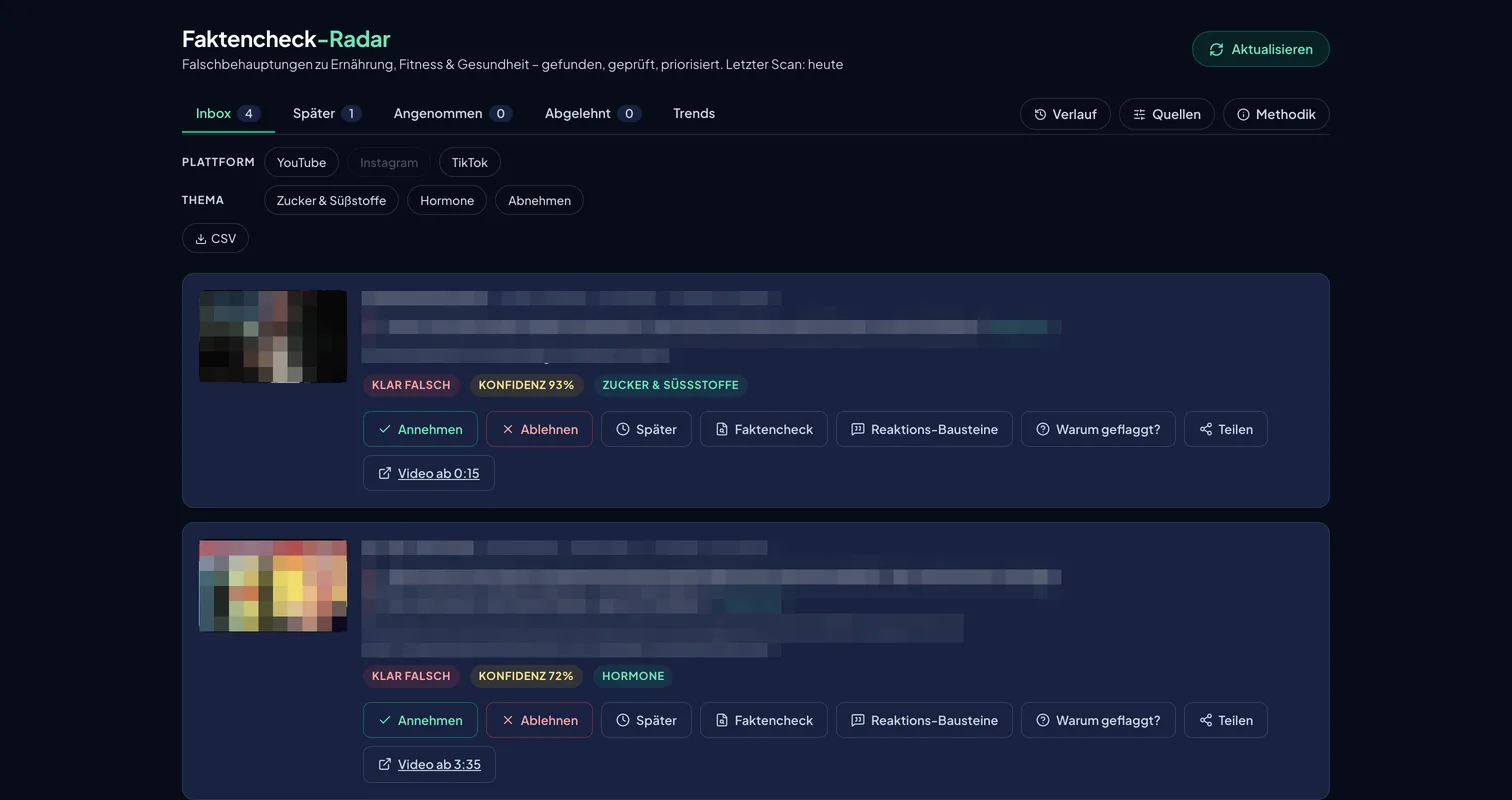
The real tool, with the claims redacted
These are screenshots of the live radar. The flagged creators' names, faces, and claim texts are pixelated on purpose: the whole point of the system is that accusations stay behind a human review, so we do not republish them in a blog post either. The structure is what matters here.
The review inbox. Each card carries the verdict, the model's confidence, the topic, a timestamped deep link, and the accept-or-reject decision that stays human. Identities and claims redacted.The methodology tab, shown to every user of the tool. The funnel tells the story: hundreds of videos found, three checking passes, and only a handful of claims survive into the inbox.
What we learned
Three decisions that make it trustworthy
1
One model pass is an opinion; the devil's advocate makes it a verdict. When the output can accuse a named person of spreading falsehoods, precision beats recall by a mile. The adversarial pass exists to kill borderline verdicts before a human ever sees them, and it does.
2
Ground every claim in a quote, and verify the quote in code. The model must show the exact sentence it heard, and the pipeline checks that sentence exists in the transcript. A claim without a verifiable quote is discarded, whatever the model's confidence says. That single rule removes the whole class of invented evidence.
3
End the automation at a suggestion. The radar collects, checks, ranks, and then stops. A person makes the only decision that touches the public, and every rejection flows back as a counterexample, so the judge gets stricter with use instead of drifting.
FAQ
Questions we get about the radar
What does the fact-check radar do?
It scans German-language YouTube, TikTok and Instagram on a schedule for viral claims about nutrition, fitness and health, checks each claim against a curated library of documented falsehoods and scientific consensus, and drops only the clearly false, high-reach ones into a review inbox where the creator decides what to react to.
How does it avoid false accusations?
Four defenses stack: every extracted claim must carry a verbatim quote that code re-verifies against the transcript; the verdict model is instructed never to call something clearly false when in doubt; a separate adversarial pass then tries to scientifically defend every clearly-false verdict and downgrades anything defensible; and a human reviews every claim before anything happens publicly.
Is it fully automated?
The scanning and checking run on a schedule without supervision. Publishing is not automated at all: the radar only fills an inbox, a person accepts or rejects each claim, and an accepted claim does nothing more than notify the team by email. Rejections flow back into the system as counterexamples, so the judge gets stricter over time.
Can you build a monitoring radar like this for us?
Yes. The same pattern fits brand monitoring, compliance watching, or tracking competitor claims: scheduled collection, adversarial AI verification with quote grounding, a hard daily budget cap, and a human review inbox. Book a call and we will scope it.
This is what a two-day client build looks like
Scheduled collection, adversarial verification, a human gate, and a budget cap: the same engineering discipline behind our AI Search Visibility work, pointed at a different feed. If your team needs a radar over something, we can scope it in one call.
Related build: the AI-search radar uses the same collect-dedup-review skeleton on a different subject. We also teach operators to build systems like this, hands-on. Balázs runs the build sessions at Agent-J+.